


Khám Phá 7 Thư Viện Python Chuyên Nghiệp Cho Data Analyst
Khám phá 7 thư viện Python chuyên nghiệp giúp Data Analyst tối ưu hóa phân tích dữ liệu, xử lý thông tin nhanh chóng và nâng cao hiệu quả công việc của bạn!
Nội dung bài viết
Python từ lâu đã trở thành "ngôi sao sáng" trong lĩnh vực phân tích dữ liệu, được ưa chuộng bởi sự linh hoạt và kho thư viện phong phú. Đối với một Data Analyst, việc nắm vững các thư viện Python không chỉ giúp xử lý dữ liệu nhanh chóng mà còn tối ưu hóa quy trình làm việc. Vậy đâu là những thư viện hàng đầu mà bạn không thể bỏ qua? Hãy cùng khám phá danh sách 7 thư viện Python chuyên nghiệp cho Data Analyst chi tiết nhất qua bài viết dưới đây.
7 Thư Viện Python Chuyên Nghiệp Cho Data Analyst
Python trở thành công cụ hàng đầu cho phân tích dữ liệu không chỉ nhờ vào cú pháp đơn giản, mà còn nhờ kho thư viện phong phú hỗ trợ mạnh mẽ cho các Data Analyst. Từ việc xử lý dữ liệu, trực quan hóa đến xây dựng mô hình học máy, mỗi thư viện đều có một vai trò riêng biệt, giúp bạn tiết kiệm thời gian và tối ưu hóa công việc. Dưới đây là 7 thư viện Python chuyên nghiệp mà bất kỳ Data Analyst nào cũng nên biết và sử dụng.
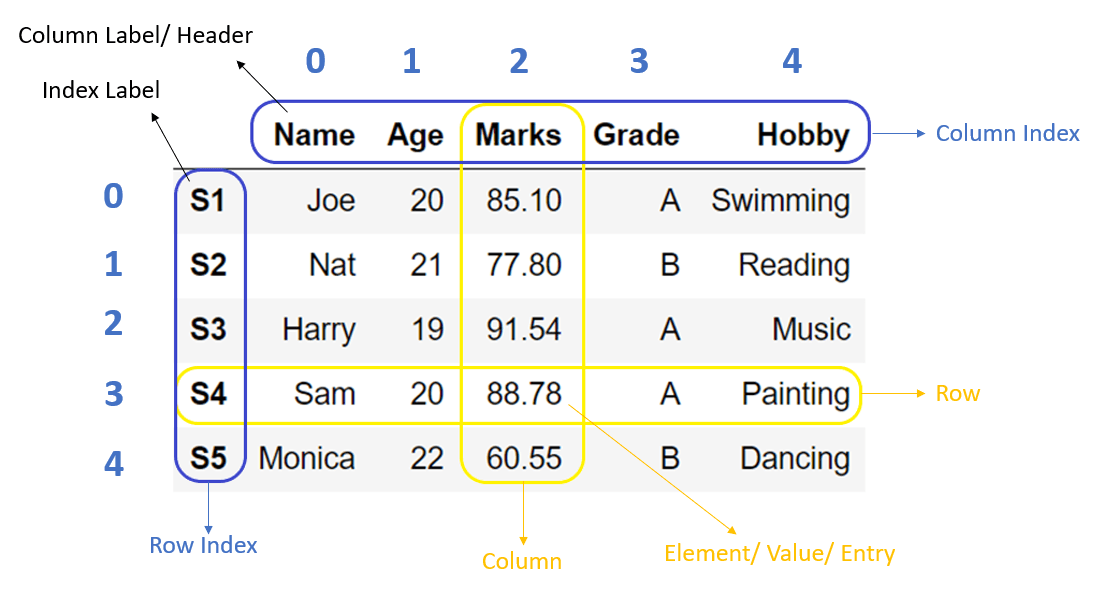
1. Pandas
Pandas là một trong những thư viện Python mạnh mẽ và phổ biến nhất dành cho Data Analyst. Được thiết kế chuyên biệt để xử lý và thao tác dữ liệu, Pandas giúp bạn thực hiện các công việc phức tạp như:
- Quản lý dữ liệu dạng bảng (DataFrame) với hàng triệu dòng và cột.
- Lọc, sắp xếp, và nhóm dữ liệu chỉ với vài dòng lệnh.
- Chuyển đổi dữ liệu thô thành dữ liệu có cấu trúc, dễ sử dụng hơn.
Ứng dụng thực tế:
Pandas thường được sử dụng để làm sạch dữ liệu, một bước cực kỳ quan trọng trước khi phân tích. Ví dụ, bạn có thể loại bỏ các giá trị thiếu hoặc tính toán giá trị trung bình cho cột dữ liệu chỉ trong vài giây.
Ví dụ sử dụng cơ bản:
import pandas as pd
# Tạo DataFrame
data = {'Ten': ['An', 'Binh', 'Cuong'], 'Tuoi': [25, 30, 35]}
df = pd.DataFrame(data)
# Hiển thị dữ liệu
print(df)
Kết quả sẽ là một bảng gọn gàng hiển thị thông tin về "Tên" và "Tuổi" của từng người. Pandas không chỉ dễ sử dụng mà còn tiết kiệm rất nhiều thời gian trong việc phân tích dữ liệu.
2. NumPy
Nếu bạn cần làm việc với các phép toán số học hoặc xử lý dữ liệu dạng mảng, NumPy chính là "cánh tay phải" không thể thiếu. Thư viện này giúp bạn làm việc với các mảng đa chiều (arrays) nhanh hơn nhiều so với cách thông thường.
Tính năng nổi bật:
- Cung cấp các hàm toán học mạnh mẽ (như tổng, trung bình, và tiêu chuẩn).
- Xử lý dữ liệu lớn với hiệu suất cao.
- Dễ dàng tích hợp với các thư viện khác như Pandas và TensorFlow.
Ứng dụng thực tế:
Bạn có thể sử dụng NumPy để tính toán ma trận, chuẩn hóa dữ liệu, hoặc làm các phép toán liên quan đến phân tích thống kê.
Ví dụ:
import numpy as np
# Tạo mảng số học
array = np.array([1, 2, 3, 4, 5])
# Tính tổng và trung bình
print("Tong:", np.sum(array))
print("Trung binh:", np.mean(array))
Chỉ với vài dòng lệnh, NumPy giúp bạn tính toán và xử lý dữ liệu một cách hiệu quả. Nếu bạn đang làm việc với dữ liệu lớn hoặc các thuật toán phức tạp, NumPy chắc chắn là thư viện nên sử dụng.
>> Xem thêm: Python và phân tích dữ liệu: Một sự kết hợp hoàn hảo
3. Matplotlib
Khi nói đến trực quan hóa dữ liệu, Matplotlib là thư viện cơ bản nhất mà bất kỳ Data Analyst nào cũng nên nắm rõ. Nó cung cấp khả năng tạo các biểu đồ đơn giản, từ biểu đồ cột, đường đến biểu đồ tròn.
Tính năng nổi bật:
- Dễ dàng tùy chỉnh biểu đồ theo ý muốn.
- Hỗ trợ nhiều kiểu biểu đồ phù hợp với các dạng dữ liệu khác nhau.
- Tích hợp tốt với các thư viện khác như Pandas và NumPy.
Ứng dụng thực tế:
Matplotlib thường được sử dụng để tạo các biểu đồ đơn giản và nhanh chóng. Ví dụ, bạn có thể vẽ biểu đồ đường để theo dõi sự thay đổi doanh số qua các tháng hoặc biểu đồ cột để so sánh lợi nhuận giữa các sản phẩm.
4. Seaborn
Nếu bạn đang tìm kiếm một cách để tạo các biểu đồ đẹp mắt và chuyên nghiệp hơn, Seaborn là lựa chọn lý tưởng. Được xây dựng trên nền tảng của Matplotlib, thư viện này giúp đơn giản hóa việc tạo ra các biểu đồ nâng cao và trông bắt mắt hơn.
Seaborn không hoàn toàn thay thế Matplotlib mà thường được sử dụng cùng nhau. Trong nhiều trường hợp, bạn có thể dùng Seaborn để tạo biểu đồ và Matplotlib để tùy chỉnh chi tiết, chẳng hạn như thêm chú thích hoặc điều chỉnh kích thước biểu đồ.
Tính năng nổi bật:
- Tích hợp sẵn các kiểu biểu đồ nâng cao, như biểu đồ phân phối (distribution plots), biểu đồ hộp (box plots) và biểu đồ nhiệt (heatmaps).
- Tự động hóa việc tùy chỉnh màu sắc và bố cục.
- Hoạt động tốt với các DataFrame của Pandas, giúp bạn dễ dàng trực quan hóa dữ liệu.
Ứng dụng:
Seaborn thường được sử dụng để trực quan hóa các mối quan hệ phức tạp giữa các biến. Ví dụ, bạn có thể tạo biểu đồ phân tán (scatter plot) để xem xét mối tương quan giữa hai biến hoặc biểu đồ nhiệt để hiển thị ma trận tương quan.
Ví dụ:
import matplotlib.pyplot as plt
import seaborn as sns
# Dữ liệu mẫu
import pandas as pd
data = {'Điem so': [50, 60, 70, 80], 'Thoi gian hoc': [2, 3, 4, 5]}
df = pd.DataFrame(data)
# Biểu đồ phân tán
sns.scatterplot(data=df, x='Thoi gian hoc', y='Điem so')
plt.title('Moi quan he giua Thoi gian hoc và Diem so')
plt.show()
>> Tìm hiểu:
- Hướng Dẫn Từ A Đến Z Về Các Kiểu Dữ Liệu Trong Python
- Tối Ưu Hóa Việc Xử Lý Chuỗi Với Hàm Split Trong Python
5. Scikit-learn
Nếu bạn quan tâm đến lĩnh vực học máy (Machine Learning), Scikit-learn chính là công cụ không thể bỏ qua. Đây là thư viện Python hàng đầu dành cho các Data Analyst muốn thực hiện các thuật toán học máy mà không cần quá nhiều kiến thức chuyên sâu về lập trình.
Tính năng nổi bật:
- Cung cấp các thuật toán học máy phổ biến, như hồi quy tuyến tính (Linear Regression), phân cụm (Clustering), và cây quyết định (Decision Trees).
- Hỗ trợ tính năng tiền xử lý dữ liệu, chia dữ liệu thành tập huấn luyện và kiểm tra.
- Tích hợp tốt với NumPy và Pandas.
Ứng dụng thực tế:
Scikit-learn có thể được sử dụng để dự đoán xu hướng bán hàng dựa trên dữ liệu lịch sử hoặc phân loại khách hàng thành các nhóm dựa trên hành vi mua sắm.
Ví dụ:
Bạn có thể sử dụng Scikit-learn để dự đoán giá nhà dựa trên các đặc điểm như diện tích, số phòng ngủ và vị trí.
from sklearn.linear_model import LinearRegression
import numpy as np
# Dữ liệu mẫu
X = np.array([[40], [50], [60]]) # Dien tich nha (m2)
y = np.array([100, 150, 200]) # Gia nha (trieu VND)
model = LinearRegression()
model.fit(X, y)
# Dự đoán giá nhà diện tích 70 m2
print(model.predict([[70]]))
6. TensorFlow
Trong thời đại dữ liệu lớn, TensorFlow nổi bật như một công cụ mạnh mẽ cho các Data Analyst muốn đào sâu vào học sâu (Deep Learning). Được phát triển bởi Google, thư viện này cung cấp mọi thứ bạn cần để xây dựng và triển khai các mô hình học sâu.
Tính năng nổi bật:
- Khả năng xử lý dữ liệu lớn và xây dựng các mạng nơ-ron nhân tạo phức tạp.
- Tương thích với các thiết bị GPU, giúp tăng tốc xử lý.
- Hỗ trợ cả việc triển khai mô hình trên đám mây và các thiết bị di động.
Ứng dụng:
TensorFlow thường được sử dụng trong phân tích hình ảnh (image analysis), nhận dạng giọng nói (speech recognition), và dự đoán dữ liệu chuỗi thời gian (time series forecasting).
>> Tìm hiểu: Python Foundation in Data Analytics
7. Keras
Được xây dựng như một lớp API cho TensorFlow, Keras mang đến sự đơn giản và dễ sử dụng. Đây là thư viện hoàn hảo cho những ai mới bắt đầu với học sâu nhưng không muốn đối mặt với quá nhiều phức tạp.
Tính năng nổi bật:
- Giao diện thân thiện, dễ học và dễ làm việc.
- Hỗ trợ nhiều kiểu mạng nơ-ron, từ mạng nơ-ron tuần tự (Sequential Models) đến mạng nơ-ron hợp nhất (Functional Models).
- Tích hợp sẵn các công cụ để tiền xử lý dữ liệu, xây dựng và huấn luyện mô hình.
Ứng dụng:
Keras cho phép bạn dễ dàng tạo ra các mô hình dự đoán, như dự đoán xu hướng giá cổ phiếu hoặc phân loại hình ảnh đơn giản.
Ví dụ mô hình đơn giản:
Tạo một mô hình mạng nơ-ron để phân loại dữ liệu.
from keras.models import Sequential
from keras.layers import Dense
# Khởi tạo mô hình
model = Sequential()
model.add(Dense(32, input_dim=10, activation='relu')) # Lớp ẩn
model.add(Dense(1, activation='sigmoid')) # Lớp đầu ra
# Biên dịch và huấn luyện
model.compile(optimizer='adam', loss='binary_crossentropy', metrics=['accuracy'])
Với Keras, bạn có thể tập trung vào việc thử nghiệm các mô hình thay vì loay hoay với các chi tiết phức tạp.
Cách Chọn Thư Viện Phù Hợp
Khi làm việc với dữ liệu, việc chọn thư viện Python phù hợp không chỉ giúp tối ưu hóa hiệu suất mà còn giúp bạn tiết kiệm thời gian và công sức. Dưới đây là một số yếu tố quan trọng bạn cần cân nhắc:
1. Dựa trên mục đích công việc
Mỗi thư viện Python đều được thiết kế để giải quyết những bài toán cụ thể:
- Nếu cần xử lý dữ liệu cơ bản: Pandas là sự lựa chọn hoàn hảo.
- Để trực quan hóa dữ liệu: Hãy bắt đầu với Matplotlib hoặc Seaborn.
- Khi bạn làm việc với học máy: Scikit-learn sẽ là trợ thủ đắc lực.
- Đối với học sâu: TensorFlow hoặc Keras là lựa chọn không thể bỏ qua.
Hãy đặt câu hỏi: công việc của bạn yêu cầu gì? Từ đó, chọn thư viện phù hợp để đạt hiệu quả tốt nhất.
2. So sánh hiệu năng giữa các thư viện
Hiệu năng của thư viện là yếu tố then chốt nếu bạn xử lý lượng dữ liệu lớn hoặc yêu cầu tốc độ cao. Một số gợi ý so sánh:
- Pandas có thể hơi chậm với dữ liệu cực lớn; trong trường hợp này, bạn nên cân nhắc sử dụng Dask để thay thế.
- Matplotlib đủ tốt cho các biểu đồ cơ bản, nhưng nếu bạn muốn biểu đồ phức tạp và trực quan hơn, Seaborn sẽ vượt trội.
- Với học sâu, TensorFlow mạnh mẽ hơn khi xử lý dữ liệu lớn, trong khi Keras dễ sử dụng hơn cho những mô hình đơn giản.
Bằng cách hiểu rõ ưu và nhược điểm của từng thư viện, bạn sẽ lựa chọn công cụ phù hợp với nhu cầu thực tế, đồng thời tận dụng tối đa khả năng của chúng.
Lưu ý rằng, đôi khi sự kết hợp giữa nhiều thư viện như Scikit-learn và Pandas, hoặc TensorFlow và Keras, có thể mang lại hiệu quả cao hơn. Hãy linh hoạt và thử nghiệm để tìm ra giải pháp tối ưu nhất!
Với sự hỗ trợ của 7 thư viện Python chuyên nghiệp trên, công việc phân tích dữ liệu không chỉ trở nên dễ dàng mà còn hiệu quả hơn bao giờ hết. Mỗi thư viện đều có những điểm mạnh riêng, phù hợp với từng mục đích cụ thể, giúp bạn tối ưu hóa quy trình làm việc và đưa ra những quyết định chính xác hơn. Hãy bắt đầu tìm hiểu và thử nghiệm để chọn ra công cụ phù hợp nhất cho dự án của mình.

Các khóa học
- Mastering AWS : From Basics to Applications Specialized
- Data Engineer Track Specialized
- AI & DASHBOARD – CHỈ 990K Hot
- Excel for Business Intelligence Analyst Bestseller
- Combo Python Level 1 & Level 2 Bestseller
- Combo Power BI Level 1 & Level 2 Bestseller
- Business Intelligence Track Hot
- RPA UiPath Nâng Cao: Chiến Thuật Automation Cho Chuyên Gia Specialized
- RPA UiPath cho Người Mới Bắt Đầu: Thành Thạo Automation Chỉ Trong 1 Ngày Specialized
- Business Analyst Fast Track Bestseller
- Business Analyst Bestseller
- Mastering VBA: From Basics to Applications Bestseller
Đăng ký tư vấn khóa học
*Vui lòng nhập số điện thoại của bạn
*Vui lòng nhập họ tên của bạn
*Vui lòng chọn giới tính
*Vui lòng chọn 1 trường

